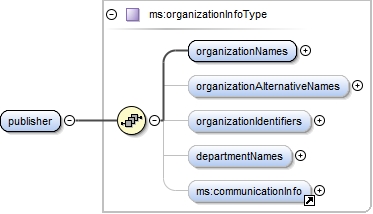
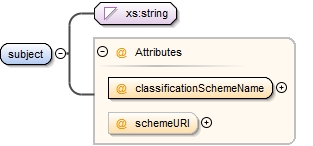
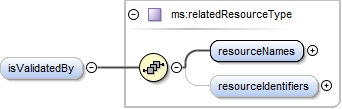
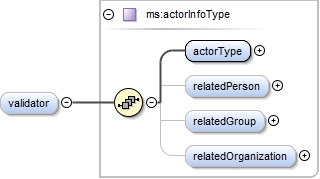
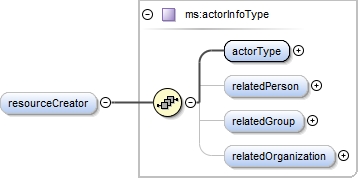
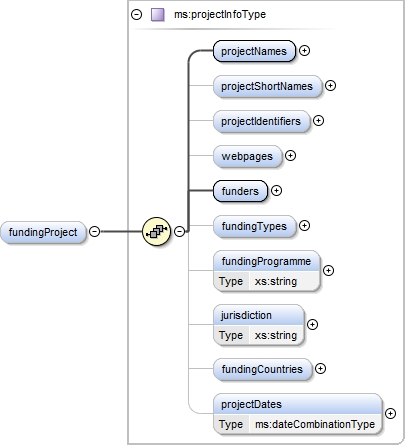
| enumeration |
http://w3id.org/meta-share/omtd-share/Solr |
Solr format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TabularFormat |
Any format based on columns
|
| enumeration |
http://w3id.org/meta-share/omtd-share/ConllFormat |
Formats used in the CoNLL Shared Tasks
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2009 |
The CoNLL 2009 format targets semantic role labeling. Columns are tab-separated. Sentences
are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2006 |
The CoNLL 2006 (aka CoNLL-X) format targets dependency parsing. Columns are tab-separated.
Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2008 |
The CoNLL 2008 format targets syntactic and semantic dependencies. Columns are tab-separated.
Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2012 |
The CoNLL 2012 format targets semantic role labeling and coreference. Columns are
tab-separated. Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/ConllU |
Format used for CoNLL.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2002 |
The CoNLL 2002 format encodes named entity spans. Fields are separated by a single
space. Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2000 |
The CoNLL 2000 format represents POS and Chunk tags. Fields in a line are separated
by spaces. Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2003 |
The CoNLL 2004 format encodes named entity spans and chunk spans. Fields are separated
by a single space. Sentences are separated by a blank new line. Named entities and
chunks are encoded in the IOB1 format. I.e. a B prefix is only used if the category
of the following span differs from the category of the current span.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Csv |
Data format with comma-separated values
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MsExcel |
Data format for Microsoft Excel documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tsv |
Format for files with tab-separated values
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Imscwb |
A tab-separated format with limited markup (e.g. for sentences, documents, but not
recursive structures like parse-trees) used by the IMS Open Corpus Workbench.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/DatabaseFormat |
Formats used for databases
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Jdbc |
For JDBC databases
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MsAccessDatabase |
Data format for Microsoft Access database
|
| enumeration |
http://w3id.org/meta-share/omtd-share/DocumentFormat |
Any format used for documents (textual resources)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Rtf |
Rich Text Format; proprietary data format of Microsoft
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Postscript |
Data format for PostScript files
|
| enumeration |
http://w3id.org/meta-share/omtd-share/BionlpFormats |
Formats used for BioNLP shared tasks
|
| enumeration |
http://w3id.org/meta-share/omtd-share/BionlpSt2013A1_a2 |
Format used in BioNLP Shared Task 2013
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Bionlp |
File format used for the BioNLP Shared Task format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Json_genia |
JSON format of the Genia dataset
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MsExcel |
Data format for Microsoft Excel documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pdf |
Data format for PDF files (Portable Document Format)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pls |
Data format according to the Pronunciation Lexicon Specification (PLS)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xhtml |
Data format for XHTML (Extensible HyperText Markup Language)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Html |
HTML format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Html5Microdata |
Format according to the specifications of HTML5 Microdata
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tex |
Data format for documents using Tex (a typesetting system)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MsWord |
Data format for Microsoft Word documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Cochrane |
Format used in Cochrane texts
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Latex |
Data format for documents using LaTeX (a high-quality typesetting system very popular
for scientific documents)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pubmed |
Textual format used for PubMed articles
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Sgml |
SGML format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Text |
Default value for the format of textual files; a textual file should be human-readable
and must not contain binary data
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xmi |
Data format for the XML Metadata Interchange (XMI), which is an Object Management
Group (OMG) standard for exchanging metadata information via Extensible Markup Language
(XML)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Json_ld |
Data format encoding Linked Data using JSON
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikiFormats |
Superclass for wiki formats
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MediaWikiMarkup |
Wiki markup for formatting
|
| enumeration |
http://w3id.org/meta-share/omtd-share/UimaCasFormat |
Formats used for the UIMA CAS (Common Analysis System) objects
|
| enumeration |
http://w3id.org/meta-share/omtd-share/BinaryCas |
Binary format used for CAS data
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Uima_json |
UIMA serialisation in JSON
|
| enumeration |
http://w3id.org/meta-share/omtd-share/SerializedCas |
The CAS is the native data model used by UIMA; there are various ways of saving CAS
data, using XMI, XCAS, or binary formats; this is for the serialized format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/AnnotationFormat |
Any format used for annotated textual documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tgrep2 |
Format for TGrep2 (search engine for searching syntactic parse trees represented as
bracketed structures)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Chat |
CHAT (Codes for the Human Analysis of Transcripts) transcription format; used by CHILDES
corpora
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xces |
Data format for documents and corpora using the XCES standard (Corpus Encoding Standard
for XML), cf. http://www.xces.org/
|
| enumeration |
http://w3id.org/meta-share/omtd-share/XcesIlspVariant |
A variant of XCES implemented for documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TigerXml |
The TIGER XML format was created for encoding syntactic constituency structures in
the German TIGER corpus. It has since been used for many other corpora as well. TIGERSearch
is a linguistic search engine specifically targetting this format. The format has
later been extended to also support semantic frame annotations.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Graf |
GrAF (Graph Annotation Format) is an extension of the Linguistic Annotation Framework
(LAF)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Naf |
The NAF format is linguistic annotation format designed for complex NLP pipelines.
NAF combines strengths of the Linguistic Annotation Framework (LAF) as described in
Ide et al. (2003) and the NLP Interchange Format (Hellman et al. 2013, NIF).
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tcf |
An XML data exchange format developed within the WebLicht architecture to facilitate
efficient interoperability between the tools; it allows the various linguistic annotations
produced by the tools within WebLicht to be stored in one document; it supports incremental
enrichment of linguistic annotations at various levels of analysis in a stand-off
XMLbased format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/AlvisEnrichedDocumentFormat |
Format for linguistic annotations of documents used for the ALVIS framework
|
| enumeration |
http://w3id.org/meta-share/omtd-share/InlineXml |
Inline XML file format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Diaml |
Format following Dialogue Act Markup Language (DiAML) which is defined within the
ISO standard 24617-2
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Brat |
BRAT stand-off format for annotations (BRAT is a online environment for collaborative
text annotation, cf. http://brat.nlplab.org/)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/I2b2 |
Format of the I2B2 challenge
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WebAnnotationFormat |
A structured model and format to enable annotations to be shared and reused across
different hardware and software platforms.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/ConllFormat |
Formats used in the CoNLL Shared Tasks
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2009 |
The CoNLL 2009 format targets semantic role labeling. Columns are tab-separated. Sentences
are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2006 |
The CoNLL 2006 (aka CoNLL-X) format targets dependency parsing. Columns are tab-separated.
Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2008 |
The CoNLL 2008 format targets syntactic and semantic dependencies. Columns are tab-separated.
Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2012 |
The CoNLL 2012 format targets semantic role labeling and coreference. Columns are
tab-separated. Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/ConllU |
Format used for CoNLL.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2002 |
The CoNLL 2002 format encodes named entity spans. Fields are separated by a single
space. Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2000 |
The CoNLL 2000 format represents POS and Chunk tags. Fields in a line are separated
by spaces. Sentences are separated by a blank new line.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Conll2003 |
The CoNLL 2004 format encodes named entity spans and chunk spans. Fields are separated
by a single space. Sentences are separated by a blank new line. Named entities and
chunks are encoded in the IOB1 format. I.e. a B prefix is only used if the category
of the following span differs from the category of the current span.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tei |
Data format for TEI-encoded (Text Encoding Initiative) texts
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Kaf |
KAF (also known as Knowledge Annotation Format) is a language neutral annotation format
representing both morpho-syntactic and semantic annotation of documents through a
stand-off multilayered structure
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Cadixe_json |
AlvisAE protocol format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Nif |
The NLP Interchange Format (NIF) is an RDF/OWL-based format that aims to achieve interoperability
between Natural Language Processing (NLP) tools, language resources and annotations;
it consists of specifications, ontologies and software (overview), which are combined
under the version identifier "NIF 2.0", but are versioned individually
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tmx |
The purpose of the TMX format is to provide a standard method to describe translation
memory data that is being exchanged among tools and/or translation vendors, while
introducing little or no loss of critical data during the process.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Html5Microdata |
Format according to the specifications of HTML5 Microdata
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Ptb |
Penn Tree Bank formats
|
| enumeration |
http://w3id.org/meta-share/omtd-share/PtbChunked |
Penn Treebank chunked format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/PtbCombined |
Penn Treebank combined format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tuepp |
Format of the Tubingen Partially Parsed Corpus of Written German (TuPP-D/Z) XML files;
TPP D/Z (http://www.sfs.uni-tuebingen.de/de/ascl/ressourcen/corpora/tuepp-dz.html)
is a collection of articles from the German newspaper taz (die tageszeitung) annotated
and encoded in a XML format.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pml |
Format according to the Prague Markup Language (http://ufal.mff.cuni.cz/jazz/PML/index_en.html);
PML is a generic data format based on XML intended for storing linguistically annotated
data, such as the Prague Dependency Treebank, also annotation lexicons, etc.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MalletLdaTopicProportions |
Topic proportions in the shape [\t]\t\t...
|
| enumeration |
http://w3id.org/meta-share/omtd-share/DkproTokenized |
DkPro format for tokenized files containing one sentence per line and tokens split
by whitespaces.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/FactoredTagLemFormat |
Factored tag lemma format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Folia |
FoLiA is an XML-based annotation format, suitable for the representation of linguistically
annotated language resources
|
| enumeration |
http://w3id.org/meta-share/omtd-share/NegraExport |
Export format for annotated corpora in the NeGra project
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MsExcel |
Data format for Microsoft Excel documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Lll |
Format of the LLL challenge
|
| enumeration |
http://w3id.org/meta-share/omtd-share/MalletLdaTopicProportionsSorted |
Topic proportions in the shape [\t]\t\t... sorted
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Emma |
Data format according to the EMMA (Extensible MultiModal Annotation markup language)
specifications, cf. https://www.w3.org/TR/2007/CR-emma-20071211/
|
| enumeration |
http://w3id.org/meta-share/omtd-share/LinkedDataFormat |
Formats used for linked data
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Json_ld |
Data format encoding Linked Data using JSON
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaFormat |
Formats used for wikipedia
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaDiscussion |
Format for wikipedia discussion pages
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaPage |
Format of wikipedia pages in the database (articles, discussions, etc)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaArticle |
Format for wikipedia articles
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaRevision |
Format for wikipedia revision pages
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaRevisionPair |
Pairs of adjacent revisions of all articles
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaLink |
Format for wikipedia links
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Blikiwikipedia |
The Java Wikipedia API (Bliki engine) is a parser library for converting Wikipedia
wikitext notation to HTML.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaArticleInfo |
Format of general article infos
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaQuery |
Reads all article pages that match a query created by the numerous parameters of this
class.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WikipediaTemplateFilteredArticle |
Format for wikipedia pages that contain or do not contain the templates specified
in the template whitelist and template blacklist
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Json |
Superclass of JSON formats
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Json_ld |
Data format encoding Linked Data using JSON
|
| enumeration |
http://w3id.org/meta-share/omtd-share/WebAnnotationFormat |
A structured model and format to enable annotations to be shared and reused across
different hardware and software platforms.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Json_genia |
JSON format of the Genia dataset
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Gate_json |
A Twitter-style JSON format used for GATE documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Uima_json |
UIMA serialisation in JSON
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Datasift_json |
Common format for social media data from http://datasift.com
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Kaf |
KAF (also known as Knowledge Annotation Format) is a language neutral annotation format
representing both morpho-syntactic and semantic annotation of documents through a
stand-off multilayered structure
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Cadixe_json |
AlvisAE protocol format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/BinaryFormat |
Any format of a computer file in which information is stored in the form of ones and
zeros, or in some other binary (two-state) sequence; used mainly for executable files
or files that need to be interpreted by a computer program
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pdf |
Data format for PDF files (Portable Document Format)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/FastInfoset |
A compressed binary encoding of GATE XML
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xml |
Superclass for grouping together XML formats
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pml |
Format according to the Prague Markup Language (http://ufal.mff.cuni.cz/jazz/PML/index_en.html);
PML is a generic data format based on XML intended for storing linguistically annotated
data, such as the Prague Dependency Treebank, also annotation lexicons, etc.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Pls |
Data format according to the Pronunciation Lexicon Specification (PLS)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/XmlBioc |
BioC is a simple format to share text data and annotations.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Emma |
Data format according to the EMMA (Extensible MultiModal Annotation markup language)
specifications, cf. https://www.w3.org/TR/2007/CR-emma-20071211/
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tei |
Data format for TEI-encoded (Text Encoding Initiative) texts
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tcf |
An XML data exchange format developed within the WebLicht architecture to facilitate
efficient interoperability between the tools; it allows the various linguistic annotations
produced by the tools within WebLicht to be stored in one document; it supports incremental
enrichment of linguistic annotations at various levels of analysis in a stand-off
XMLbased format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Folia |
FoLiA is an XML-based annotation format, suitable for the representation of linguistically
annotated language resources
|
| enumeration |
http://w3id.org/meta-share/omtd-share/BncFormat |
Data format for the XML version of the British National Corpus (http://www.natcorp.ox.ac.uk/)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/AlvisEnrichedDocumentFormat |
Format for linguistic annotations of documents used for the ALVIS framework
|
| enumeration |
http://w3id.org/meta-share/omtd-share/GateXml |
XML-based format for GATE components
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tmx |
The purpose of the TMX format is to provide a standard method to describe translation
memory data that is being exchanged among tools and/or translation vendors, while
introducing little or no loss of critical data during the process.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tuepp |
Format of the Tubingen Partially Parsed Corpus of Written German (TuPP-D/Z) XML files;
TPP D/Z (http://www.sfs.uni-tuebingen.de/de/ascl/ressourcen/corpora/tuepp-dz.html)
is a collection of articles from the German newspaper taz (die tageszeitung) annotated
and encoded in a XML format.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Owl_xml |
XML format for OWL ontologies
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TigerXml |
The TIGER XML format was created for encoding syntactic constituency structures in
the German TIGER corpus. It has since been used for many other corpora as well. TIGERSearch
is a linguistic search engine specifically targetting this format. The format has
later been extended to also support semantic frame annotations.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Rdf_xml |
Data format for RDF (Resource Description Framework) XML format; RDF/XML is a serialisation
for RDF
|
| enumeration |
http://w3id.org/meta-share/omtd-share/InlineXml |
Inline XML file format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xmi |
Data format for the XML Metadata Interchange (XMI), which is an Object Management
Group (OMG) standard for exchanging metadata information via Extensible Markup Language
(XML)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xces |
Data format for documents and corpora using the XCES standard (Corpus Encoding Standard
for XML), cf. http://www.xces.org/
|
| enumeration |
http://w3id.org/meta-share/omtd-share/XcesIlspVariant |
A variant of XCES implemented for documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xpath |
XPath is a language for addressing parts of an XML document, designed to be used by
both XSLT and XPointer.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Xhtml |
Data format for XHTML (Extensible HyperText Markup Language)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/CorpusFormat |
A format used by a specific type of corpus (collection of texts)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tcf |
An XML data exchange format developed within the WebLicht architecture to facilitate
efficient interoperability between the tools; it allows the various linguistic annotations
produced by the tools within WebLicht to be stored in one document; it supports incremental
enrichment of linguistic annotations at various levels of analysis in a stand-off
XMLbased format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/AclAnthologyCorpusFormat |
Data format specific to the ACL Anthology Reference Corpus (http://acl-arc.comp.nus.edu.sg/),
most probably version 20080325
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Tuepp |
Format of the Tubingen Partially Parsed Corpus of Written German (TuPP-D/Z) XML files;
TPP D/Z (http://www.sfs.uni-tuebingen.de/de/ascl/ressourcen/corpora/tuepp-dz.html)
is a collection of articles from the German newspaper taz (die tageszeitung) annotated
and encoded in a XML format.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/TigerXml |
The TIGER XML format was created for encoding syntactic constituency structures in
the German TIGER corpus. It has since been used for many other corpora as well. TIGERSearch
is a linguistic search engine specifically targetting this format. The format has
later been extended to also support semantic frame annotations.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Nif |
The NLP Interchange Format (NIF) is an RDF/OWL-based format that aims to achieve interoperability
between Natural Language Processing (NLP) tools, language resources and annotations;
it consists of specifications, ontologies and software (overview), which are combined
under the version identifier "NIF 2.0", but are versioned individually
|
| enumeration |
http://w3id.org/meta-share/omtd-share/AimedCorpusFormat |
Format of the Aimed corpus (225 abstracts from MEDLINE) with the gold standard sentence,
protein, protein-protein interaction annotations.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/BncFormat |
Data format for the XML version of the British National Corpus (http://www.natcorp.ox.ac.uk/)
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Web1t |
File format used by the Web1T n-gram corpus, a huge collection of n-grams collected
from the internet.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Reuters21578Sgml |
Reuters-21578 corpus in SGML format
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Imscwb |
A tab-separated format with limited markup (e.g. for sentences, documents, but not
recursive structures like parse-trees) used by the IMS Open Corpus Workbench.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/KeaCorpus |
KEA-style (Keyphrase Extraction Algorithm) corpus
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Reuters21578Txt |
Reuters-21578 corpus transformed into text format using ExtractReuters in the lucene-benchmarks
project
|
| enumeration |
http://w3id.org/meta-share/omtd-share/GateFormat |
Formats used for the GATE framework
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Datasift_json |
Common format for social media data from http://datasift.com
|
| enumeration |
http://w3id.org/meta-share/omtd-share/GateXml |
XML-based format for GATE components
|
| enumeration |
http://w3id.org/meta-share/omtd-share/FastInfoset |
A compressed binary encoding of GATE XML
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Gate_json |
A Twitter-style JSON format used for GATE documents
|
| enumeration |
http://w3id.org/meta-share/omtd-share/RdfFormats |
Formats for RDF (Resource Description Framework) resources
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Obo |
Serialization format for ontologies according to the Open Biomedical Ontologies model.
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Owl |
Superclass for formats used for OWL
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Owl_xml |
XML format for OWL ontologies
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Rdf_xml |
Data format for RDF (Resource Description Framework) XML format; RDF/XML is a serialisation
for RDF
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Nif |
The NLP Interchange Format (NIF) is an RDF/OWL-based format that aims to achieve interoperability
between Natural Language Processing (NLP) tools, language resources and annotations;
it consists of specifications, ontologies and software (overview), which are combined
under the version identifier "NIF 2.0", but are versioned individually
|
| enumeration |
http://w3id.org/meta-share/omtd-share/Turtle |
Textual syntax for RDF that allows an RDF graph to be completely written in a compact
and natural text form, with abbreviations for common usage patterns and datatypes.
|